The Second Half of Model Architecture
tldr: We spent a decade scaling computation inside layers. We forgot to scale communication between them. That’s about to change.
中文版本请见 量子位公众号。
A Chinese version of this post is published on QbitAI (WeChat).
For a decade, the recipe for progress in deep learning has been remarkably consistent: scale everything. More parameters. More data. Longer context. And it worked. Loss went down, capabilities went up, and the scaling laws told us exactly how much more to invest.
But not all scaling is created equal. Sequence length required genuine innovation, and got it: an entire ecosystem of mechanism research and systems engineering. Data scaled straightforwardly: more data, lower loss. Making models bigger, wider and deeper, seemed just as simple.
But were width and depth really contributing equally?
Not quite. Depth scaled in quantity without scaling in quality. The mechanism for how layers communicate has barely changed. Understanding why reveals something surprising, not just about depth, but about a blind spot in how we design neural architectures altogether.
The first half
To see what the first half of model architecture got right, look at what scaled well, and how.
Start with sequence length. Early Transformers handled hundreds of tokens. Getting to 128K+ required sustained creativity across multiple fronts: new attention patterns (sparse, linear, hybrid), systems engineering (FlashAttention), position encoding advances (RoPE scaling). Researchers and engineers built an entire ecosystem around this, continuously improving how tokens communicate. And the payoff went far beyond longer documents. Without this investment, the extended reasoning chains behind O1 and R1 would be far more costly. That’s what happens when you invest in how information flows along the sequence dimension.
Parameters and data were the intuitive part. Since the earliest days of deep learning, every textbook teaches us the same recipe: more data, wider layers, deeper networks, better representations. From GPT-2’s 1.5B to today’s hundreds of billions, the recipe worked. No new mechanisms needed. Just more of the same.
Except wider and deeper are not the same. Width scales naturally: GPUs love wide matrix multiplications, attention heads evolved to be more efficient, and wider hidden states fit seamlessly into existing architectures.
Depth tells a different story. Models did get deeper: 32 layers, 64, even 100+. But the mechanism for how layers communicate, x + F(x), remains essentially the same primitive ResNet introduced in 2015. There has been innovation around it (norm placement, residual scaling, cross-layer connectivity), but none displaced the “+” as the mainstream interface.
The residual connection is arguably the single most important primitive in deep learning. Without it, no 100-layer Transformers, no modern LLMs, no scaling laws. But here’s the thing about foundational solutions: sometimes they become so invisible that nobody questions whether they’re still the right answer, or just the first one that worked.
Think of it as a game of whisper, with a twist. In the standard game, person 1 whispers to person 2, who whispers to person 3. By person 18, the message is garbled. That’s a vanilla deep network: each layer only sees the previous layer’s output.
The residual connection fixes this: each person also forwards the accumulated message verbatim. Person 3 hears both person 2’s new interpretation and everything before. The original signal is always preserved, as one voice in a growing chorus.
But by person 152, you’re hearing 152 voices at once: the original message plus 151 layers of additions, all blended into a single whisper. The original words are technically in there, but buried. If person 152 needs to know what person 3 specifically said, they have to strain to pick it out of the blend.

Usually, they can’t.
This is information dilution. Each layer faces a trade-off: contribute something new and risk burying what came before, or hold back and preserve what’s already there. Many layers learn to hold back, writing little or nothing to the residual stream. The network becomes nominally deep but effectively shallow. You stack 152 layers, but many of them learn to stay quiet.
The bottleneck is not the computation within 152 layers. It’s the communication through them. CPUs hit the same wall decades ago: processors got faster until memory bandwidth couldn’t keep up, forcing the industry to pivot to caches and interconnects. Organizations hit it too: brilliant individuals, limited by how they coordinate. We have been living through the deep learning version: a decade of making each layer more powerful, while the channel between them remains a single-lane road from 2015.
So, is there a better mechanism?
The recipe
Many researchers noticed the depth bottleneck before me. Over the years, the fixes grew progressively cleverer: DenseNet, the CVPR 2017 best paper, kept every layer’s output, but at quadratic cost. Learnable weights (DenseFormer, LIMe) made it cheaper, but froze the blend after training: the same recipe for every token, every context. ByteDance’s Hyper-Connections and DeepSeek’s mHC widened the pipe to n channels with mixing matrices between them. More lanes on the highway, but information still flows layer-by-layer. No mechanism for layer 152 to reach back to layer 3.
ColorfulClouds’ MUDDFormer made the mixing dynamic, generating weights conditioned on each token’s hidden state. This gets something fundamentally right: how much you draw from each layer should depend on what you’re processing. But layer 152 decides how much to draw from layer 3 based on its own state alone, without knowing what layer 3 actually contains. It’s predicting which layers are useful, not checking.
Each step fixed a real limitation. None questioned the depth-residual frame itself.
It took me a while to see what these approaches had in common. Every one of them, from DenseNet to Hyper-Connections, answers the same implicit question: “how do we better blend layer outputs?” Better coefficients, more channels, adaptive weights. Always blending. Always accumulation. AI2’s ELMo had shown early on that different layers encode genuinely different information: syntax in shallow layers, semantics in deep ones. The conclusion everyone drew was “learn better blending weights to balance syntax and semantics.” But there is an alternative that the mainstream largely overlooked: if different layers hold different information, maybe each layer should be able to retrieve from whichever earlier layer holds what it needs, based on content, not position.
This is the category error: treating inter-layer communication as accumulation (combining signals with learned or generated coefficients) rather than retrieval (selecting information through content-based matching). In the accumulation frame, even dynamic methods generate blend weights from the current layer alone, without consulting what each source actually contains. In the retrieval frame, the query encodes what is needed, the key encodes what is available, and their comparison determines relevance. Both sides get a voice.
Back to the whisper game. Every prior method tried to produce a cleaner chorus: better enunciation, more relay channels, adaptive volume. None questioned the fundamental constraint that all voices accumulate into a single sound. None asked: what if you could simply walk back and talk to any person directly?
I think this kind of category error is pervasive in architecture design. When something works well enough, you don’t question its conceptual frame. You improve within it. It took years of increasingly creative workarounds to see that the depth residual did not need better coefficients. It needed to be replaced by a fundamentally different operation.
One that already solved this exact problem along the sequence dimension.

The second half
Once you see inter-layer communication as retrieval rather than accumulation, the natural answer is attention across depth. Several groups converged on this idea independently: Google’s DCA, Huawei’s MRLA, Hessian.AI’s Dreamer, Kimi’s AttnRes, each applying dot-product attention across layers. The convergence itself was a signal: the concept was right.
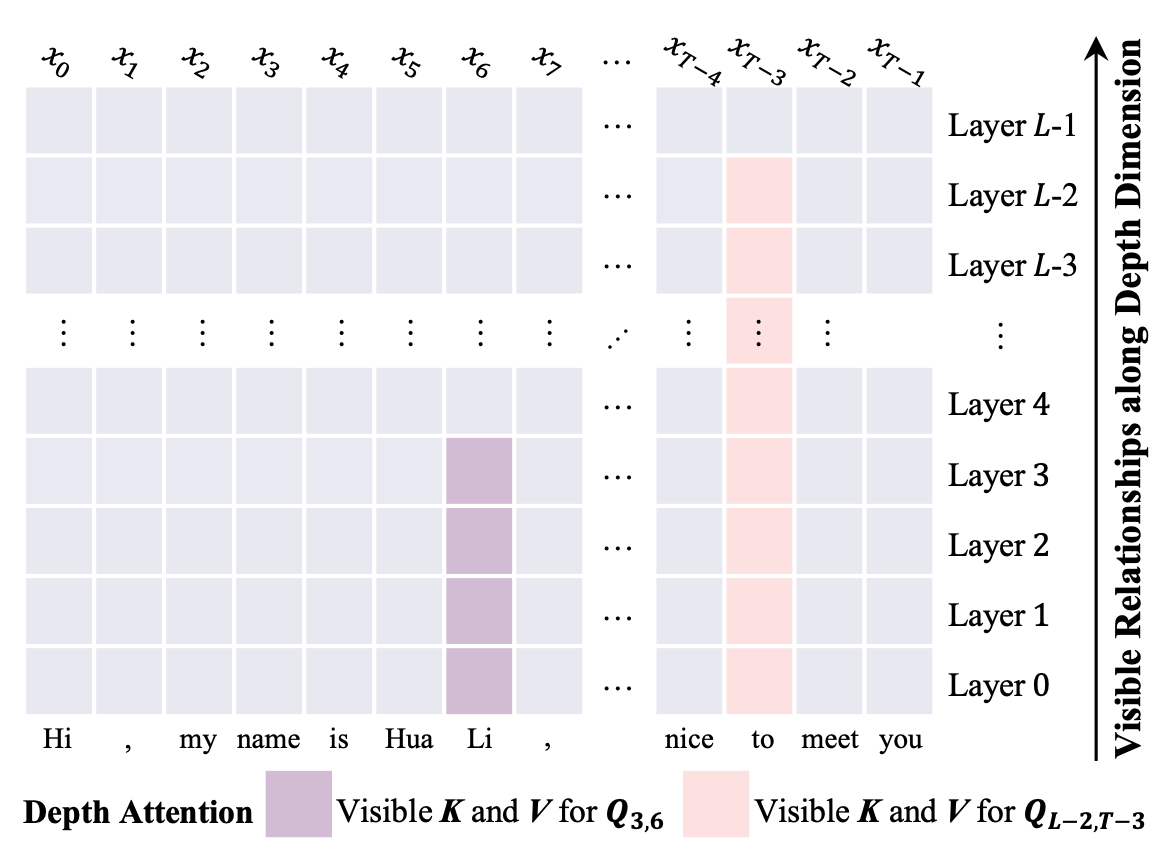
But concept and practice are different things. I’ll be honest: the first time I ran depth attention with a naive implementation, the forward-backward pass took 44,924 ms! The idea was sound; the engineering reality was brutal. Modern GPUs are optimized for large, regular matrix multiplications, not thousands of tiny attention operations across depth. An algorithm that is cheap to compute can still be painfully slow to run.
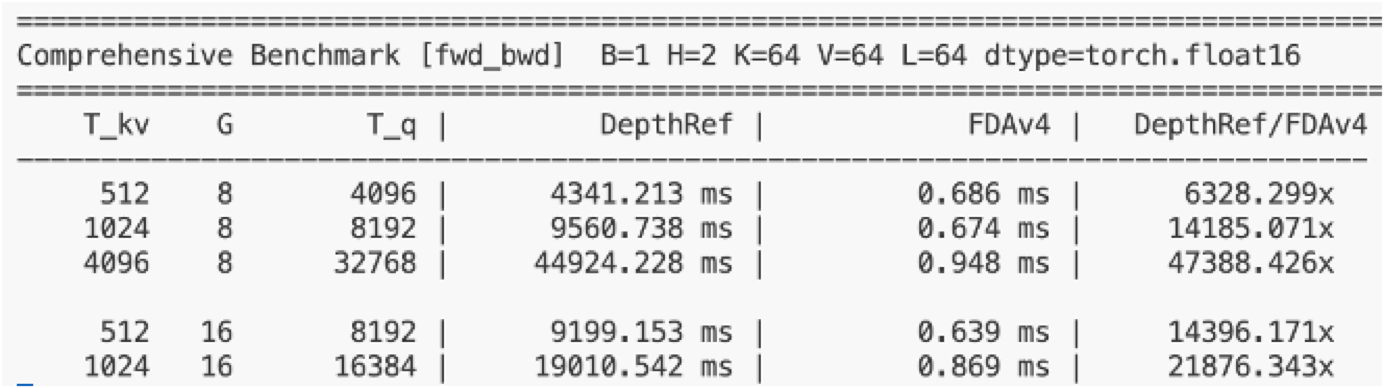
Previous methods hit an impasse: simplify depth attention for speed (losing the selective retrieval that made it worthwhile), or keep full expressivity at impractical cost. We found a way through by not simplifying the algorithm, but designing a hardware-aware implementation for the computation. Flash Depth Attention made full-expressivity depth retrieval fast enough to train at scale.
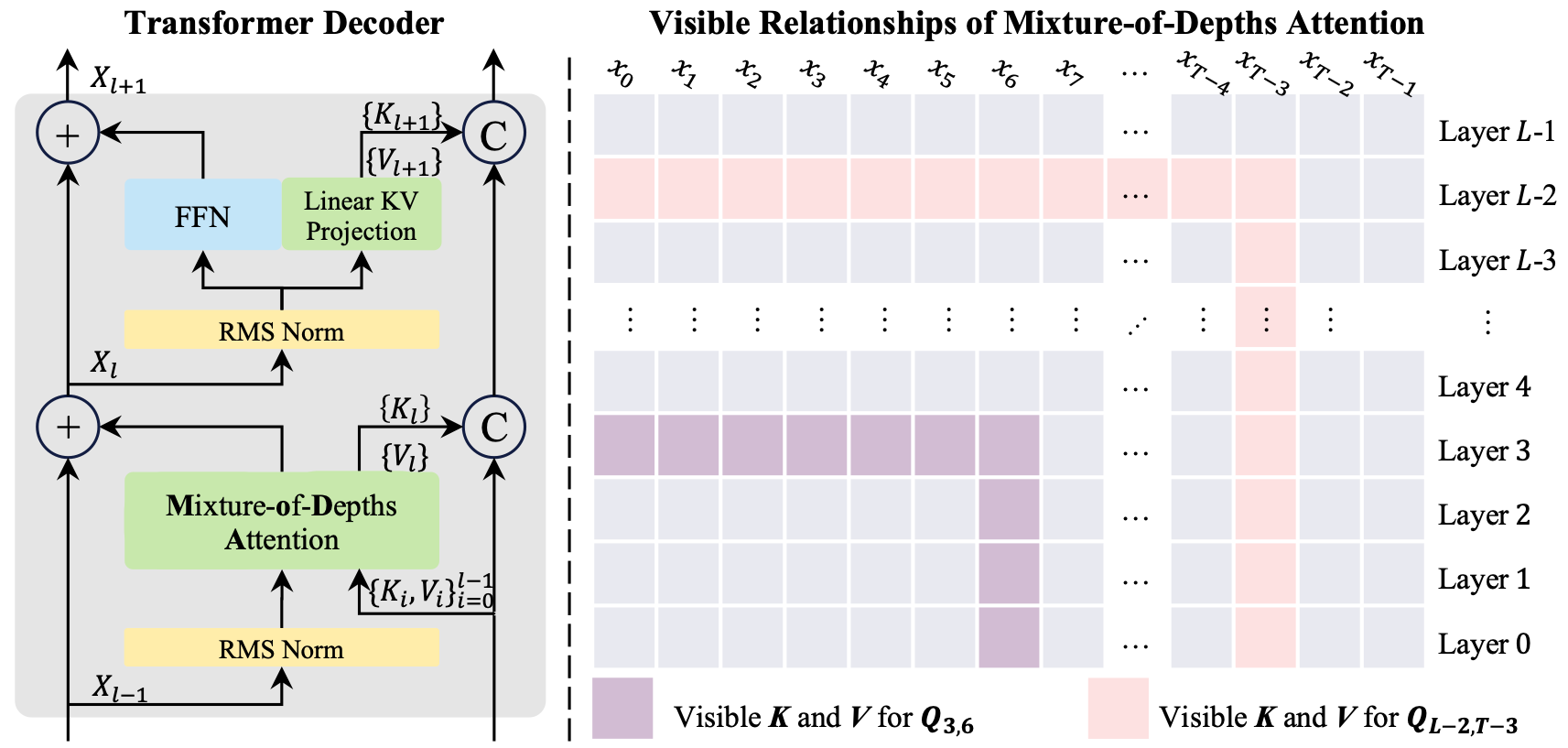
The conventional Transformer backbone pipeline is: residual connections -> sequential attention -> residual connections -> FFN (feed-forward network). With efficient depth retrieval in hand, we noticed that the main pipeline of each layer had become: depth attention -> sequence attention -> depth attention -> FFN. Three attention operations over different KV sets, sharing almost the same query. The natural move was to fuse them. Mixture-of-depths attention (MoDA) merges depth and sequence retrieval into one unified softmax. Each head jointly attends to the current layer’s sequence KV pairs and depth KV pairs from all preceding layers. Under one softmax, the model freely decides when to look across sequence tokens and when to look across layers. One operation, two dimensions of retrieval.
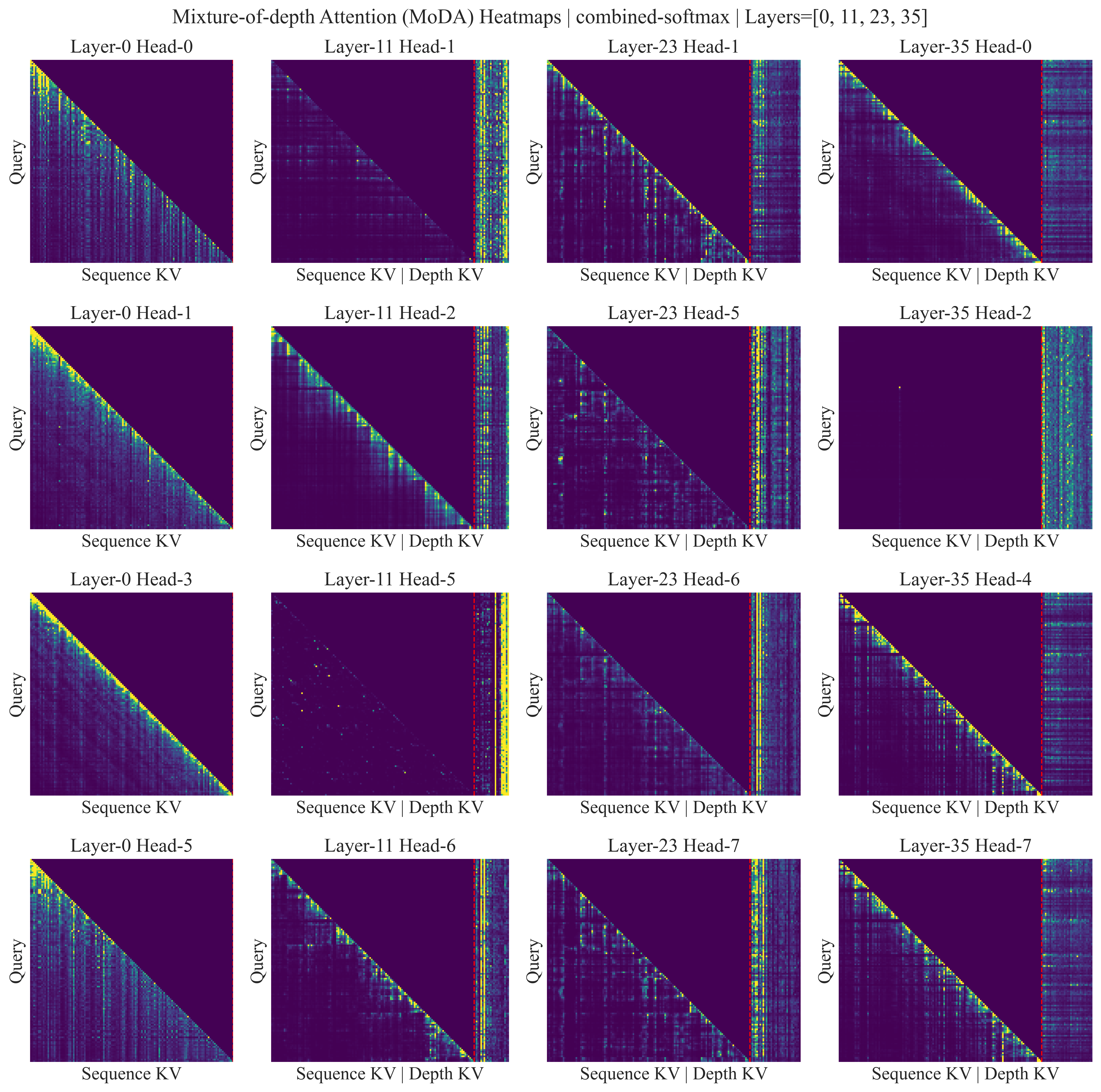
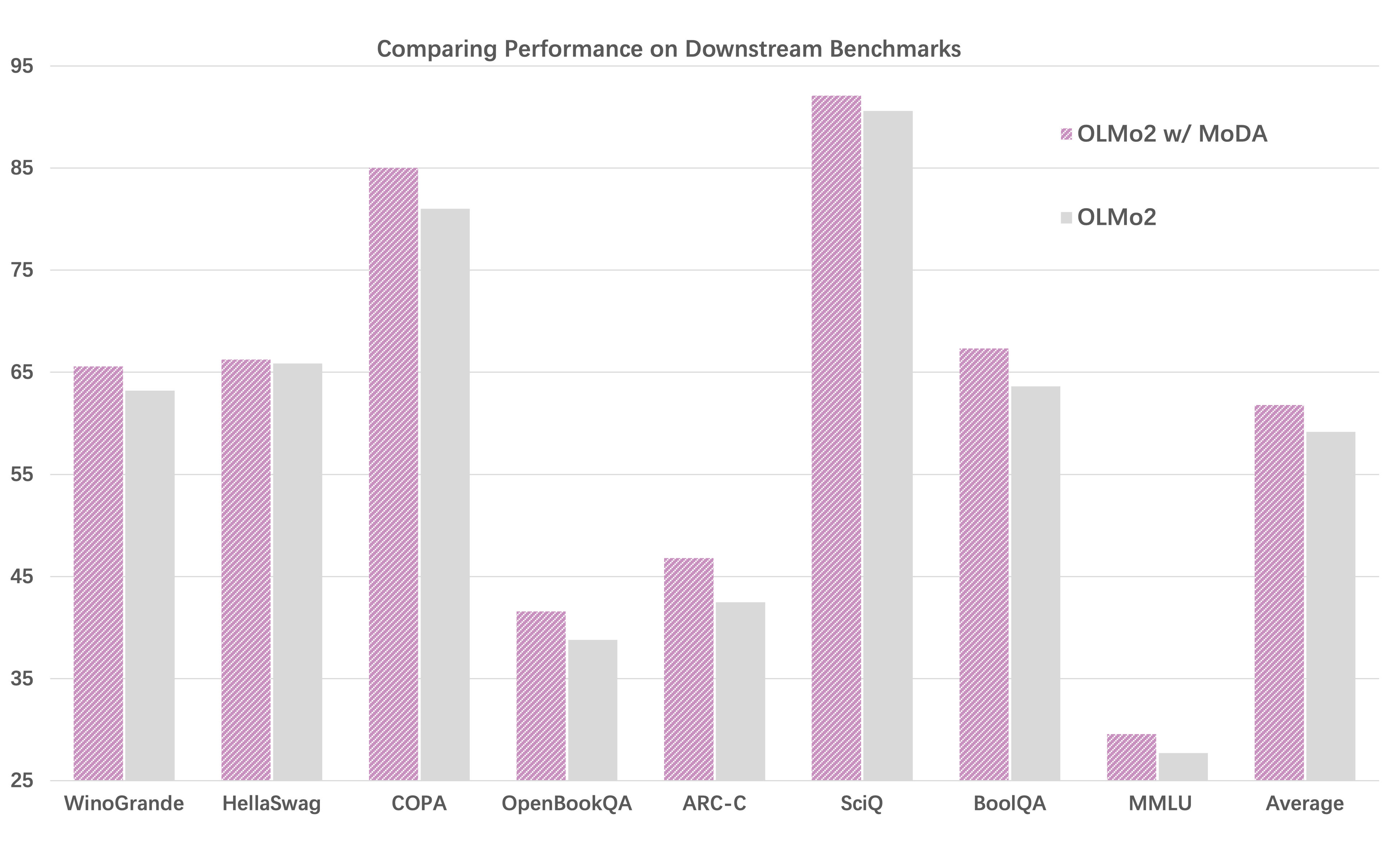
Return to the whisper game. In the residual version, person 152 strains to hear person 3 through a chorus of accumulated voices. With depth retrieval, person 152 taps person 3 on the shoulder and asks directly: “What did you say?” No intermediaries. No accumulated noise. And the results confirmed what the analogy predicts: given the ability to selectively retrieve from specific layers through depth KV, the model consistently and actively chooses to do so. The attention sink phenomenon diminishes (attention sink is a longstanding puzzle for architecture researchers, where models dump probability mass onto a few fixed tokens). This is what happens when you invest in how information flows between layers, not just within them.
The first half of model architecture was about scaling components. Longer sequences, more data, bigger models. The question was “how can we scale everything up?” It was the right question. It got us from GPT-2 to GPT-4. The second half is about scaling communication. The new question: “how well do components communicate?”
Depth is the most glaring case because the gap between what exists (additive accumulation) and what is possible (selective retrieval) is enormous. And I believe the principle generalizes. Wherever neural networks use static, data-independent channels to move information, between layers, between modalities, between time steps, there’s likely a retrieval mechanism waiting to replace the accumulation.
We spent a decade mastering how tokens talk to each other. Now it’s time to master how layers talk to each other, and eventually, how every component in a neural network talks to every other. The “+” had a great run. But it’s time to upgrade the staircase.
Welcome to the second half of model architecture.